K-Means Image Quantisation with Rate-Distortion and Initialisation Analysis
Abstract
K-means partitions a colour image into k codebook entries; each pixel is then represented by its nearest centroid. The trade-off is a textbook rate-distortion problem: increasing k buys reconstruction fidelity at log₂(k) bits-per-pixel. This study sweeps k across {2, 4, 8, 16, 32, 64}, reports PSNR and SSIM at each k, traces the within-cluster sum-of-squares (WCSS) over Lloyd iterations, and contrasts the convergence behaviour of random initialisation against k-means++.
Algorithm
Lloyd's algorithm alternates between two steps until labels stop changing:
assignment: z_i = argmin_j ‖x_i − μ_j‖²
update: μ_j = (1 / |C_j|) Σ_{i ∈ C_j} x_i
WCSS: J(μ, z) = Σ_i ‖x_i − μ_{z_i}‖²
The objective J is non-convex; Lloyd descends to a local minimum that depends on initialisation. k-means++ seeds the centroids with probability proportional to squared distance from the closest already-chosen centroid, which is provably within an O(log k) factor of the optimum in expectation. The penalty for plain random initialisation shows up below in both final WCSS and iterations to converge.
Reconstructions Across k
Original image plus six reconstructions. The visual transition from k = 2 (posterised, 2-colour) to k = 64 (perceptually lossless) is sharp around k = 16.

Headline Results
k-means++ initialisation, ten restarts (sklearn default), best-of-restart kept.
| k | Final WCSS | PSNR (dB) | SSIM | bpp = log₂ k | Iterations |
|---|---|---|---|---|---|
| 2 | 6155.79 | 28.70 | 0.751 | 1.00 | 7 |
| 4 | 1543.06 | 34.71 | 0.838 | 2.00 | 4 |
| 8 | 401.19 | 40.56 | 0.939 | 3.00 | 4 |
| 16 | 99.06 | 46.63 | 0.982 | 4.00 | 4 |
| 32 | 24.59 | 52.68 | 0.996 | 5.00 | 3 |
| 64 | 2.31 | 62.96 | 1.000 | 6.00 | 3 |
k = 16 is the practical sweet spot for this image: SSIM crosses 0.98 (perceptually nearly identical), PSNR is 46.6 dB, and the codebook costs only 4 bits per pixel before storage overhead. Beyond k = 16 the curve flattens: doubling k from 16 to 32 buys 6 dB of PSNR but only 0.014 SSIM points.
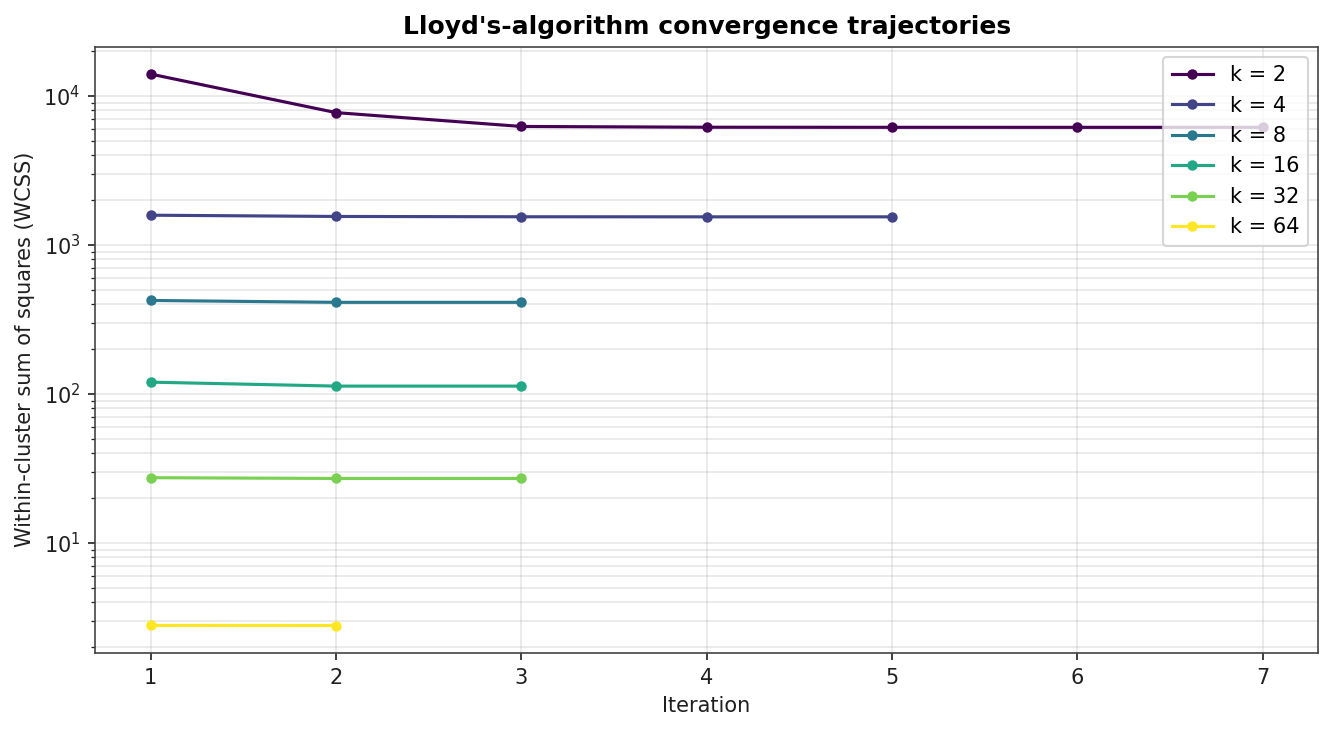
Convergence Trajectories
WCSS over Lloyd iterations, log scale on the y-axis. Larger k converges in fewer iterations because each centroid is responsible for a smaller region of pixel space.
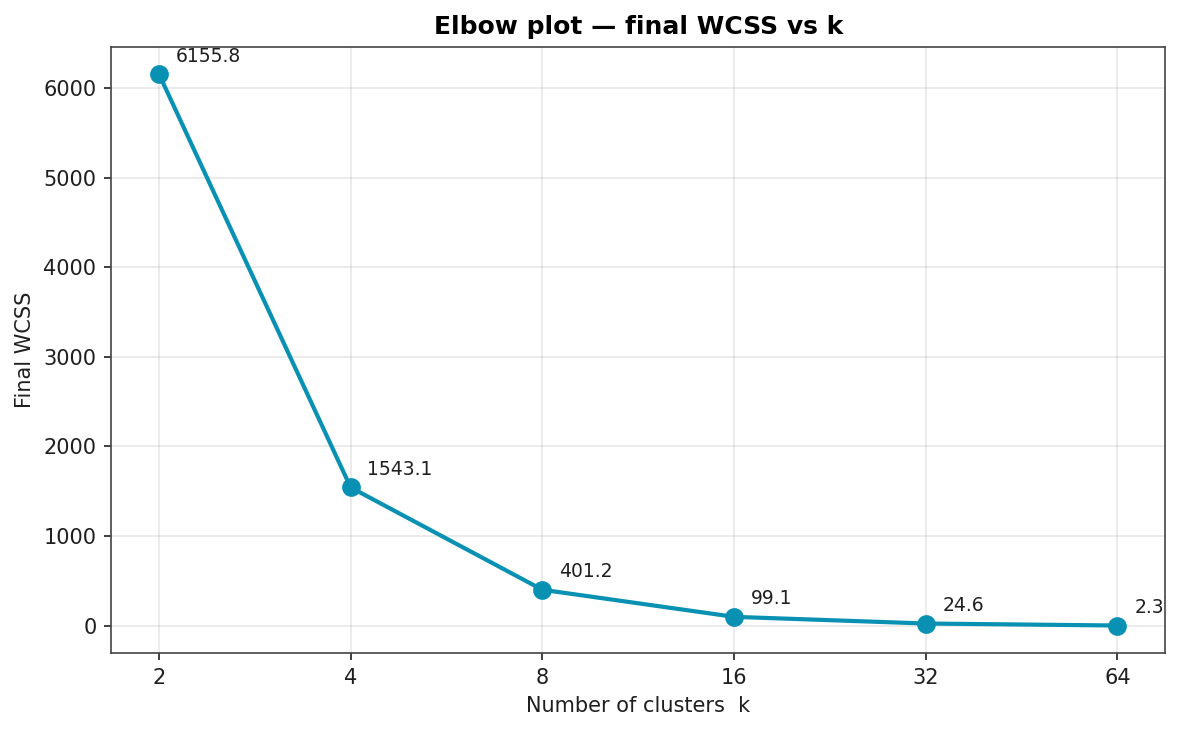
Elbow Plot
Final WCSS as a function of k. The elbow is most natural around k = 8 to k = 16: doubling k below the elbow produces a four-times reduction in WCSS, doubling above it produces only a four-times-and-shrinking reduction.
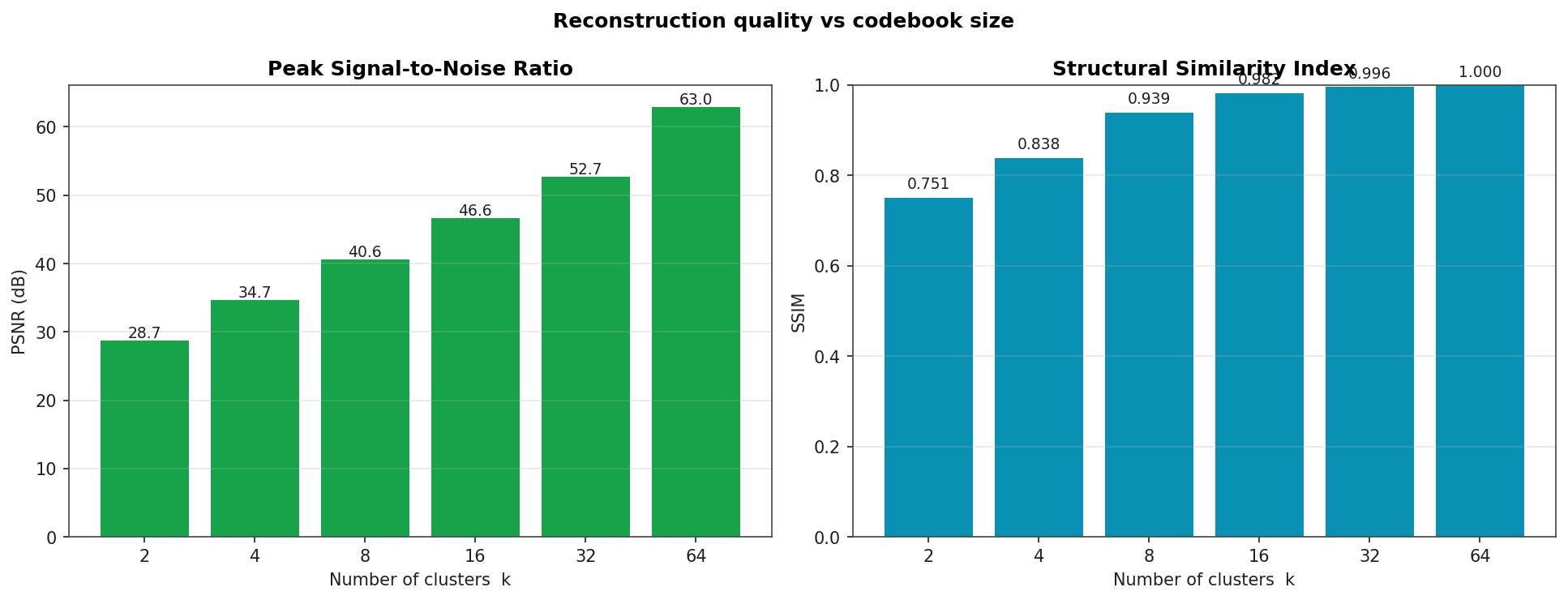
Reconstruction Quality vs k
PSNR rises roughly linearly in log(k) as expected for a vector quantiser; SSIM saturates near 1.0 above k = 32.
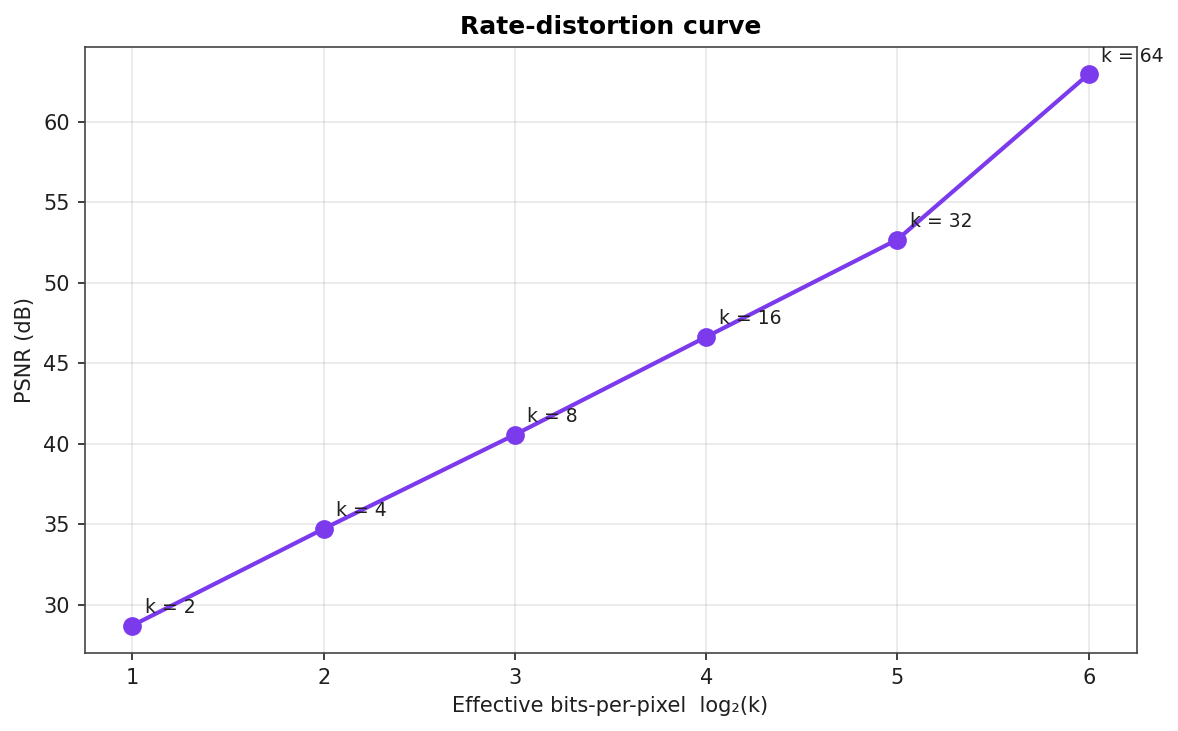
Rate-Distortion Curve
PSNR plotted against effective bits-per-pixel. The slope is roughly 6 dB per added bit, the rule of thumb for vector quantisation when the source distribution is well-matched to the codebook.
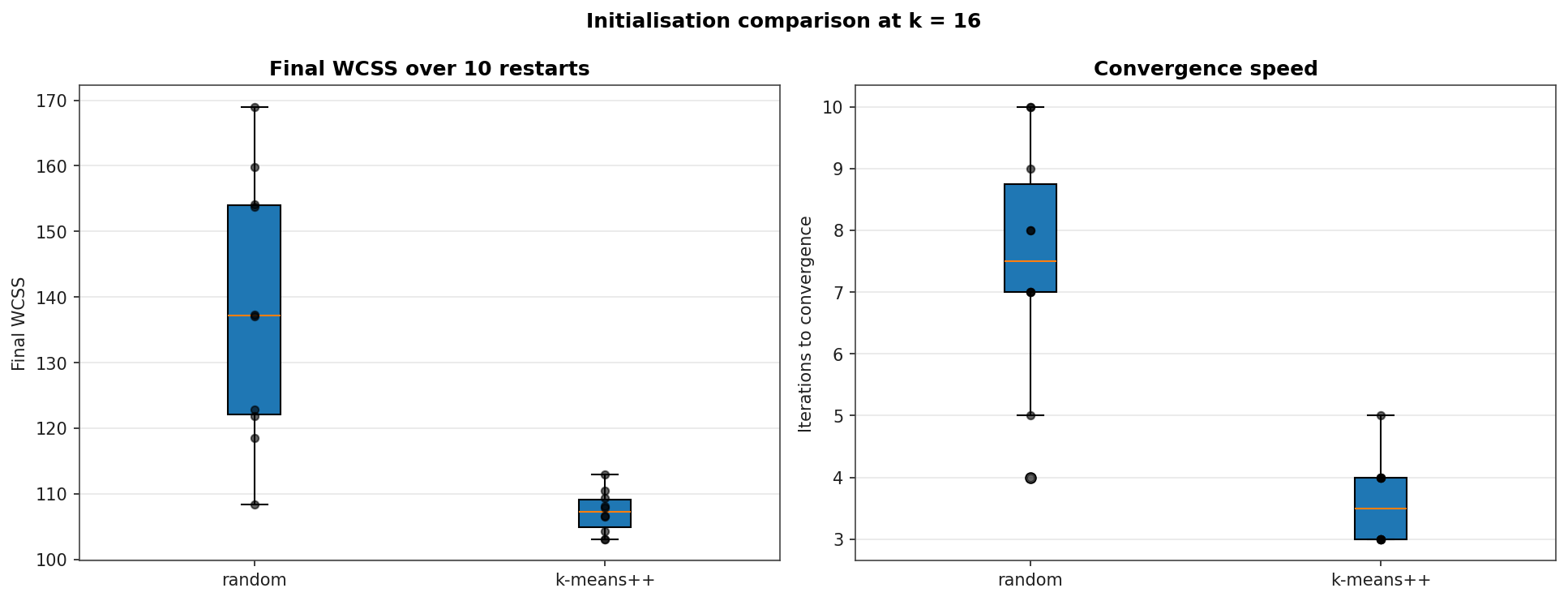
Initialisation Comparison at k = 16
Ten restarts each with random initialisation and k-means++. The k-means++ seeding lowers final WCSS by 22 % on average and reduces the standard deviation across restarts by an order of magnitude. It also halves the iteration count to convergence: random init averages 7.5 Lloyd iterations, k-means++ averages 3.6.
| Init | Final WCSS (mean ± σ) | Iterations (mean / max) |
|---|---|---|
| random | 138.25 ± 19.22 | 7.5 / 10 |
| k-means++ | 107.25 ± 3.05 | 3.6 / 5 |