Optimal Control and Avoidance for a Dubins Airplane
Abstract
A Dubins airplane (constant speed, bounded turn rate) navigates a 3-D corridor with six cylindrical no-fly pillars. The avoidance problem is solved two ways: (i) Hamilton-Jacobi reachability via dynamic programming on a state-space grid using helperOC (Mo Chen, UC Berkeley), which yields the backward reachable tube (BRT) of unsafe states and the corresponding optimal-avoidance feedback law; and (ii) a YAPPS-style trajectory optimisation that treats the obstacles as soft penalties on a smoothed cost. The two approaches are compared on the same six-pillar benchmark to expose the optimality-vs-tractability trade-off that defines this whole class of problem.
Dynamics & Problem Setup
Dubins airplane state x = (p_x, p_y, p_z, ψ) with constant speed v, bounded heading rate u ∈ [−u_max, u_max], and a fixed glide-slope schedule for p_z:
ṗ_x = v cos ψ
ṗ_y = v sin ψ
ṗ_z = v_z(t)
ψ̇ = u
The heading-rate input is bounded: u ∈ [−u_max, +u_max]. Six cylindrical obstacles {O_i} of radius r_i centred at (c_i^x, c_i^y) form the avoid-set, parameterised by the signed distance to the nearest pillar:
L(x) = min_i [ ‖(p_x, p_y) − (c_i^x, c_i^y)‖ − r_i ]
A = { x : L(x) ≤ 0 }
Method 1: HJ Reachability (helperOC)
Compute the backward reachable tube of states from which the airplane is forced into the avoid-set within horizon [0, T], regardless of control choice. The value function V(x, t) solves the Hamilton-Jacobi-Isaacs PDE:
∂V/∂t + min(0, H(x, ∇V)) = 0
V(x, T) = L(x)
H(x, p) = min_{u ∈ U} ⟨f(x, u), p⟩
The zero-sublevel set of V is the BRT; the optimal avoidance control is recovered as u*(x, t) = argmin_u ⟨f(x, u), ∇V⟩. helperOC discretises the 4-D state on a Cartesian grid and time-steps backwards with a Lax-Friedrichs scheme. This is exact (up to discretisation) but pays the curse of dimensionality: a 60⁴ grid with 0.05 s time step takes ≈ 3 minutes on a desktop CPU for this problem.
Method 2: Trajectory Optimisation (YAPPS-style penalty)
Discretise the trajectory {x_k}_{k=0}^N with N = 200 waypoints and minimise:
J = Σ_k ‖u_k‖²
+ λ_obs Σ_{k,i} max(0, r_i + ε − d_{k,i})²
+ λ_term ‖x_N − x_goal‖²
s.t. Dubins kinematics, |u_k| ≤ u_max
Three terms: control effort, a soft obstacle penalty (quadratic when inside the safety margin r_i + ε, zero outside), and a terminal cost on reaching x_goal. Solved with sequential quadratic programming. Fast (under 10 s on the same machine) but only locally optimal; the smoothed obstacle penalty can leak into A if λ_obs is too small or the initial guess threads the wrong gap.
Six-Pillar Benchmark: HJR (helperOC)
Backward-reachable tube + closed-loop trajectory under the optimal HJR feedback law on the six-pillar layout. The blue iso-surface is the BRT; the red curve is the closed-loop path that stays outside it.
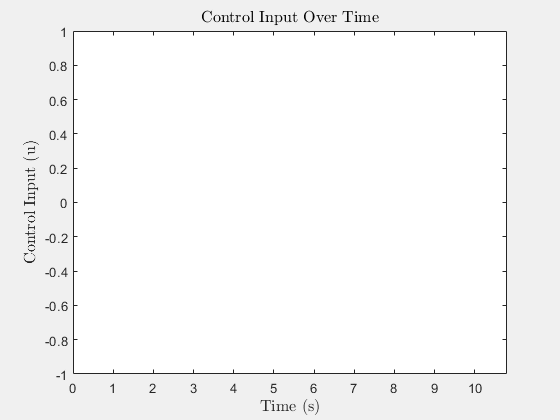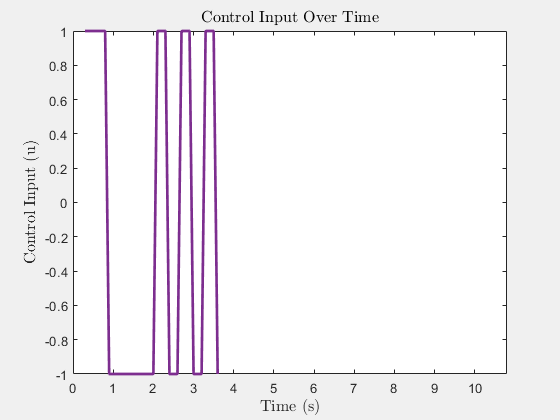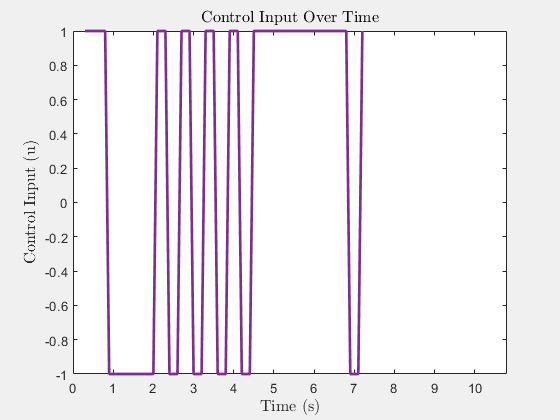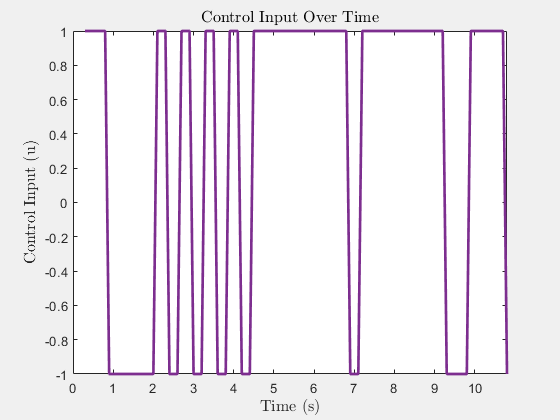
Control input u(t) (heading rate)
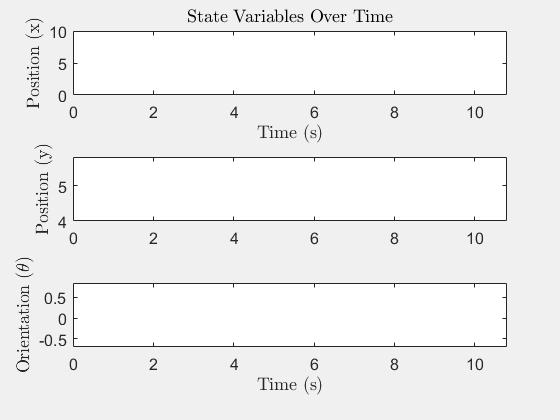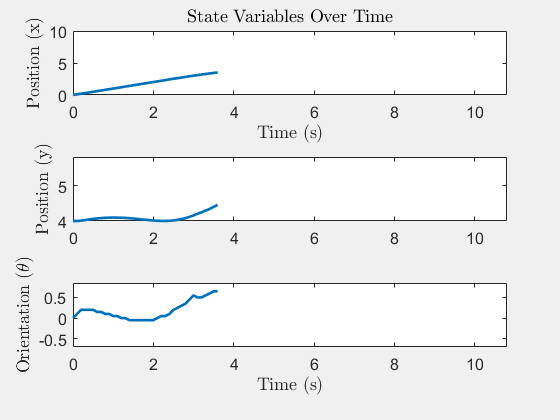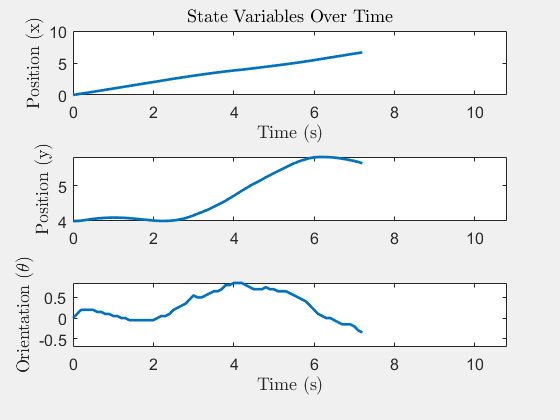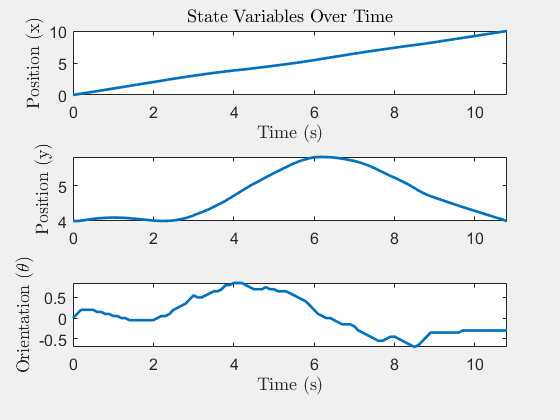
State trajectory x(t)
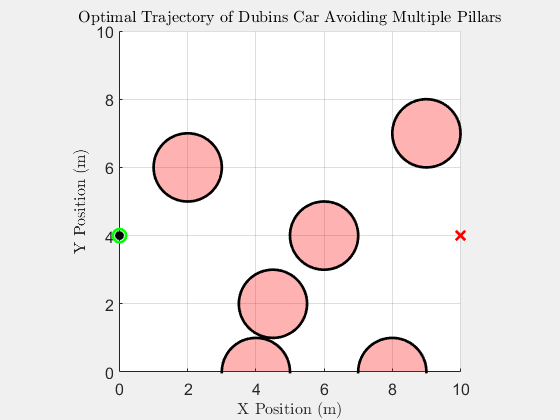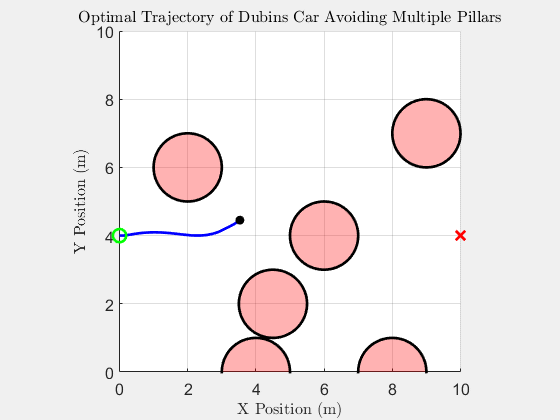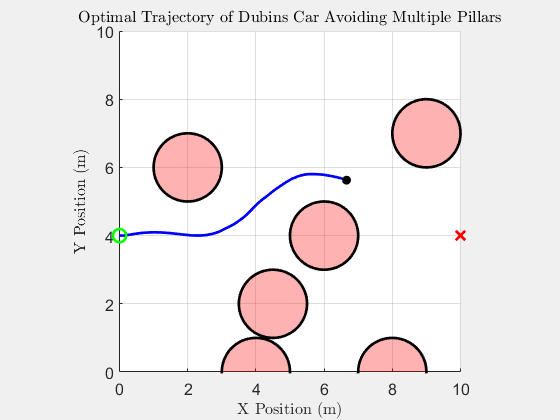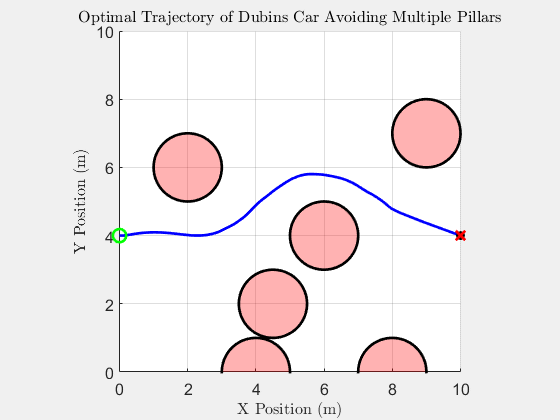
Top-down trajectory
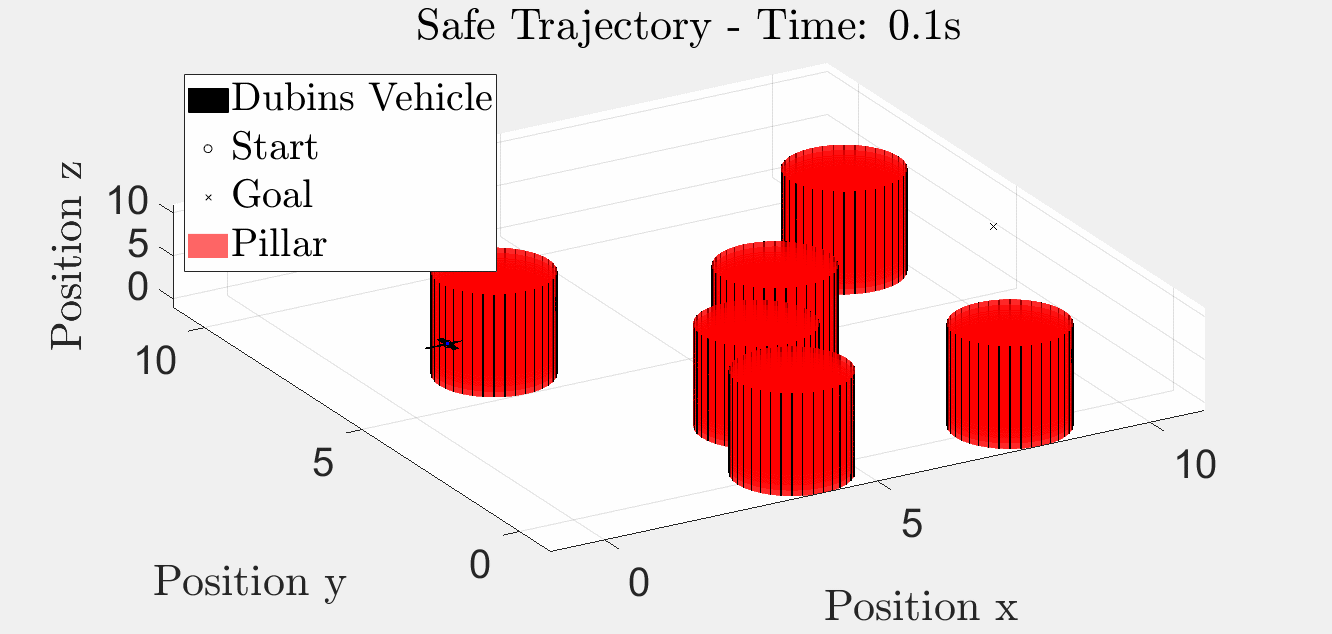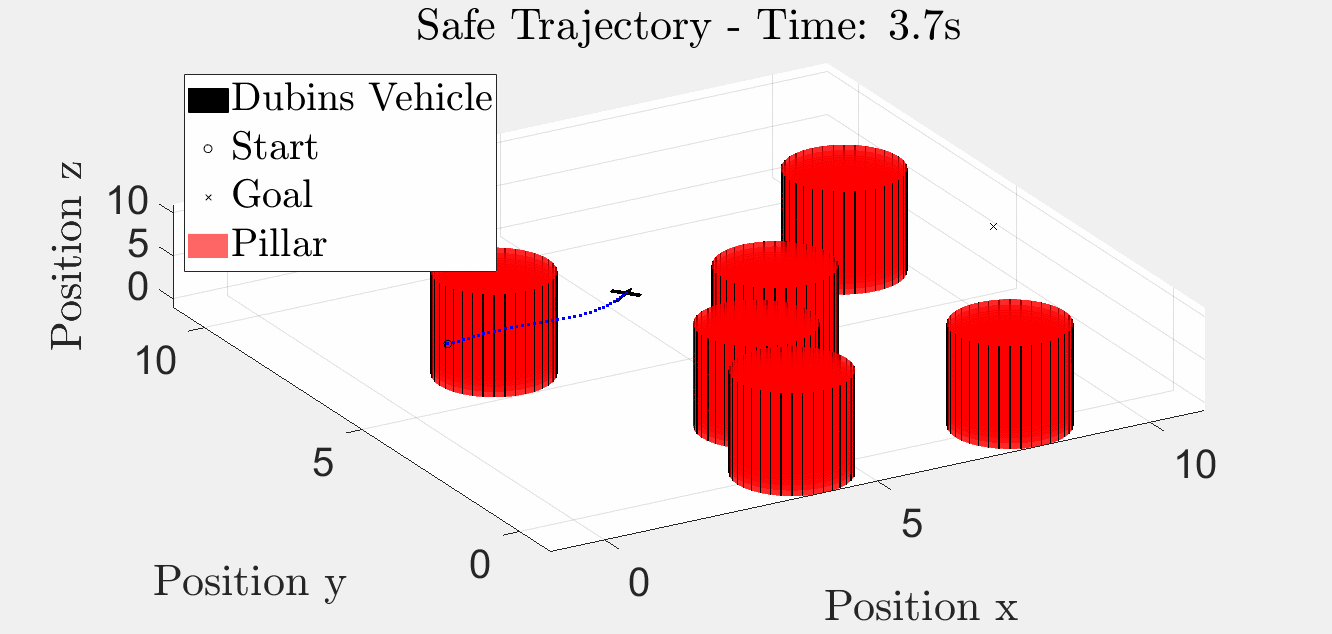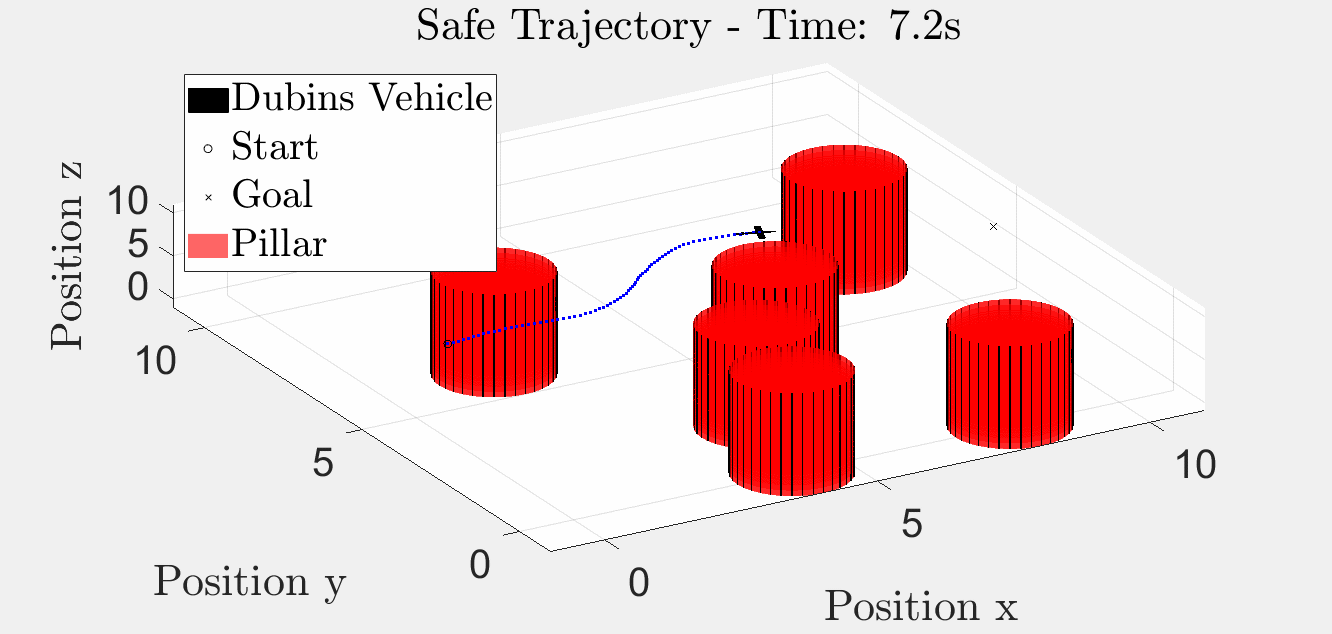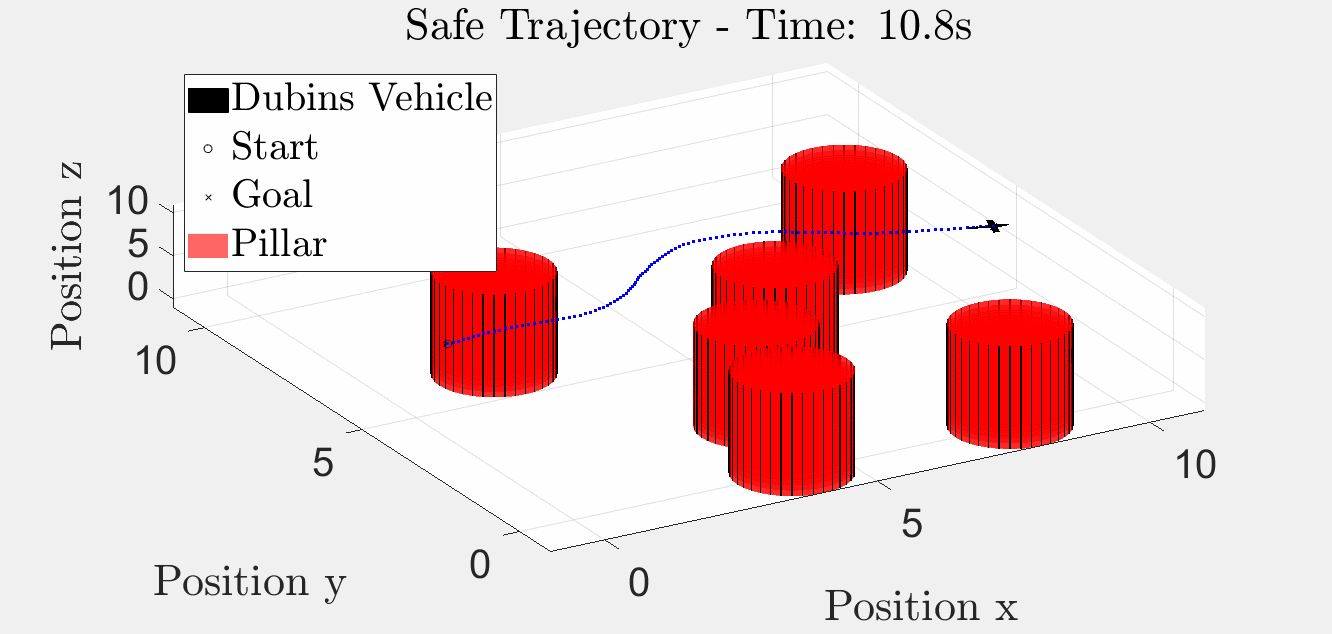
3-D animation
Six-Pillar Benchmark: YAPPS (Trajectory Optimisation)
The same scenario solved by SQP-style trajectory optimisation. The path is smoother because the obstacle penalty is smoothed; the trade-off is that there is no formal guarantee the BRT is respected, and pathological initial guesses can converge into a pillar.
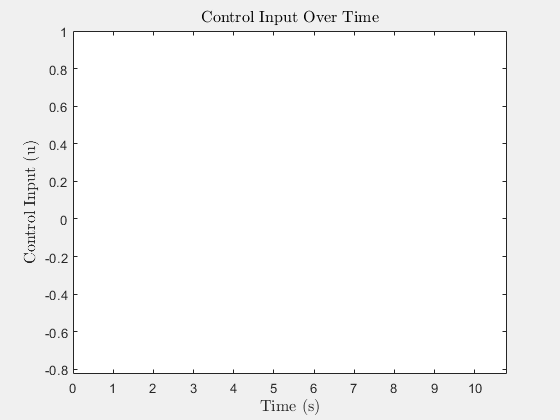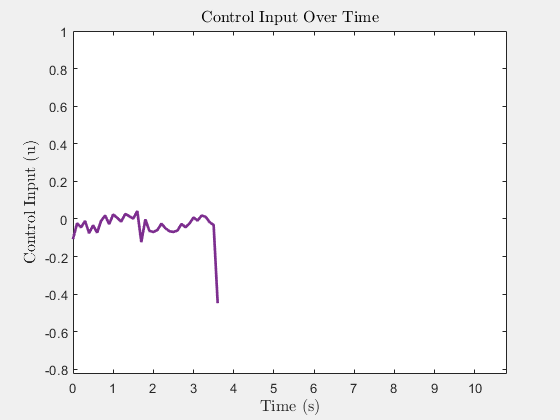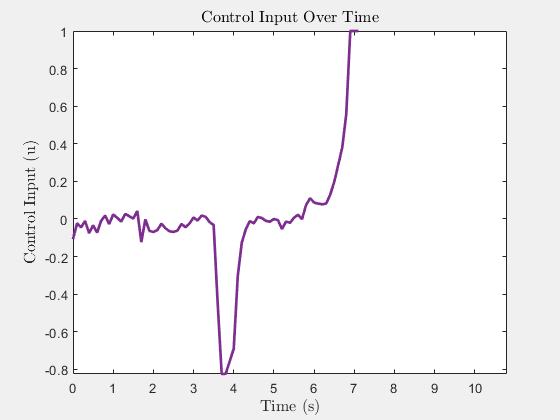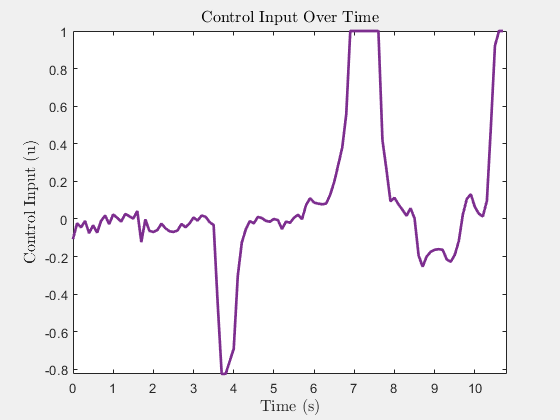
Control input u(t)
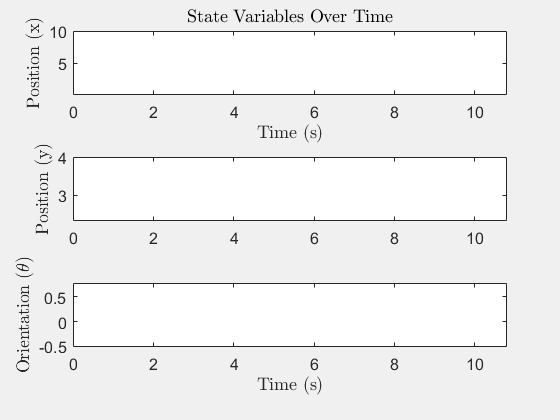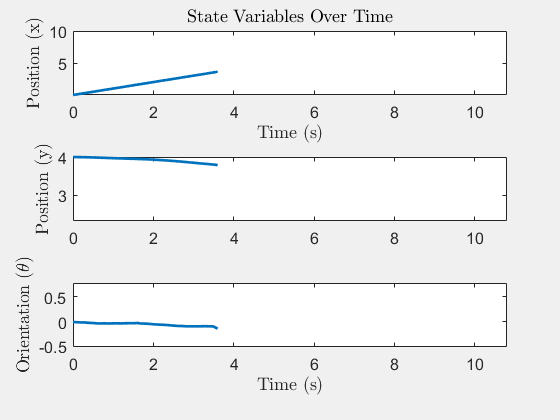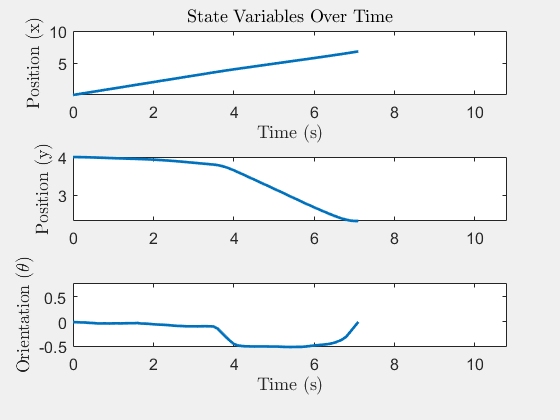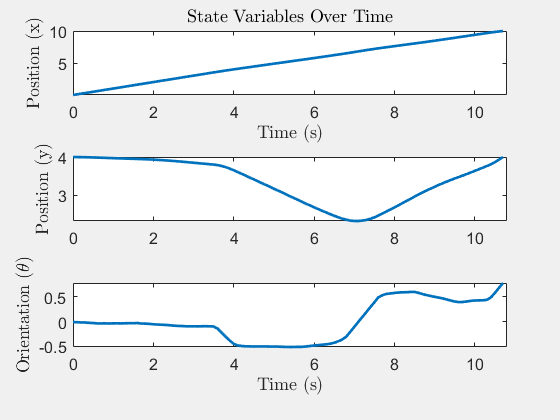
State trajectory x(t)
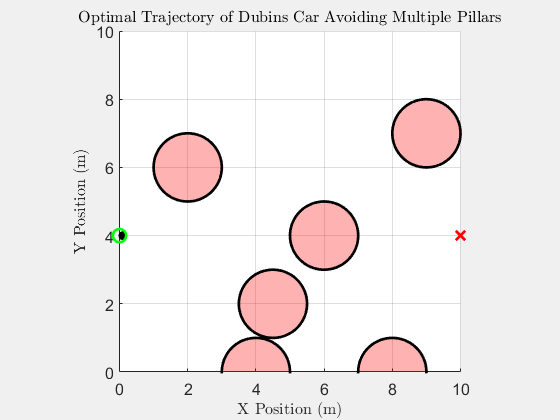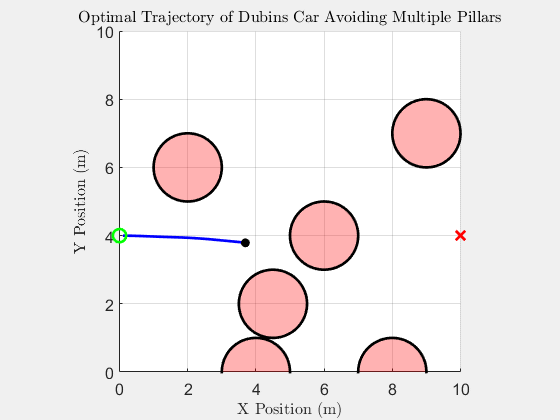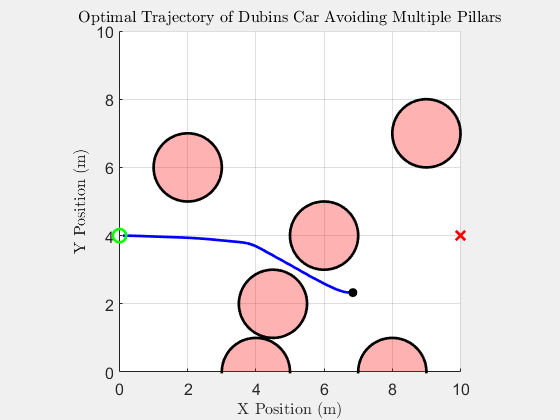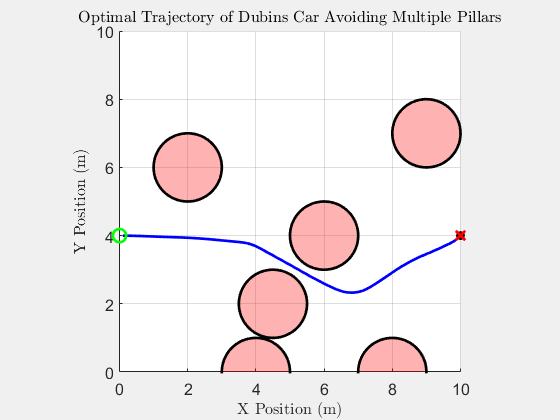
Top-down trajectory
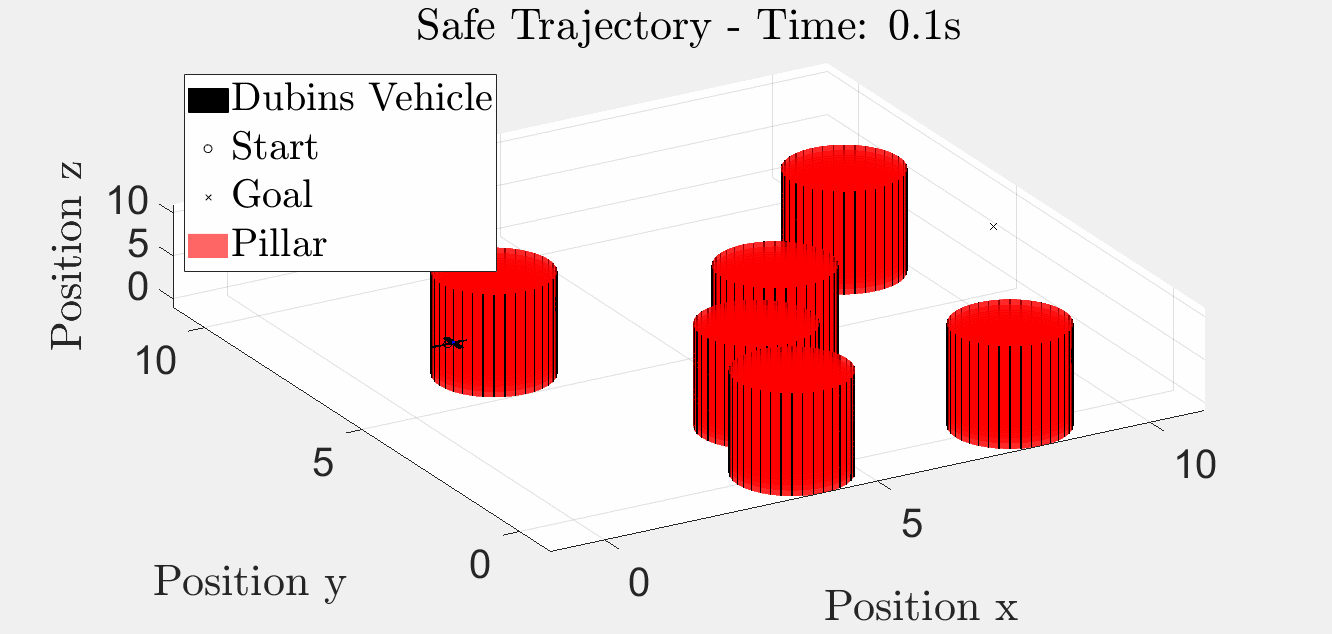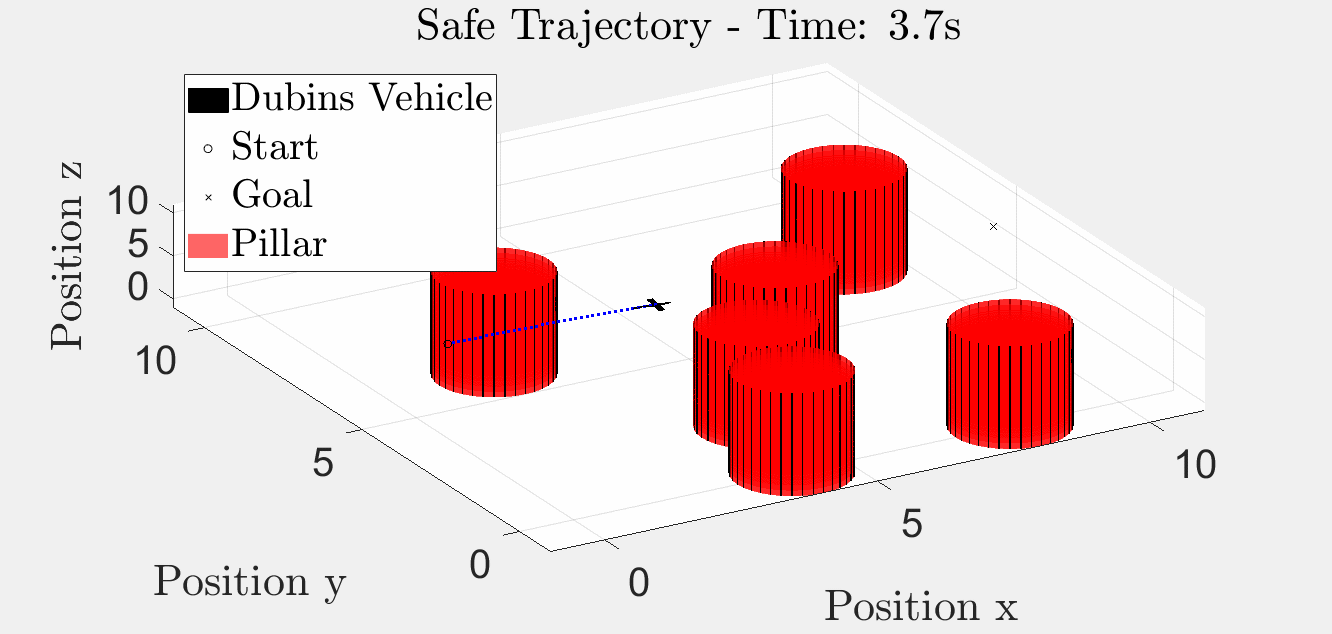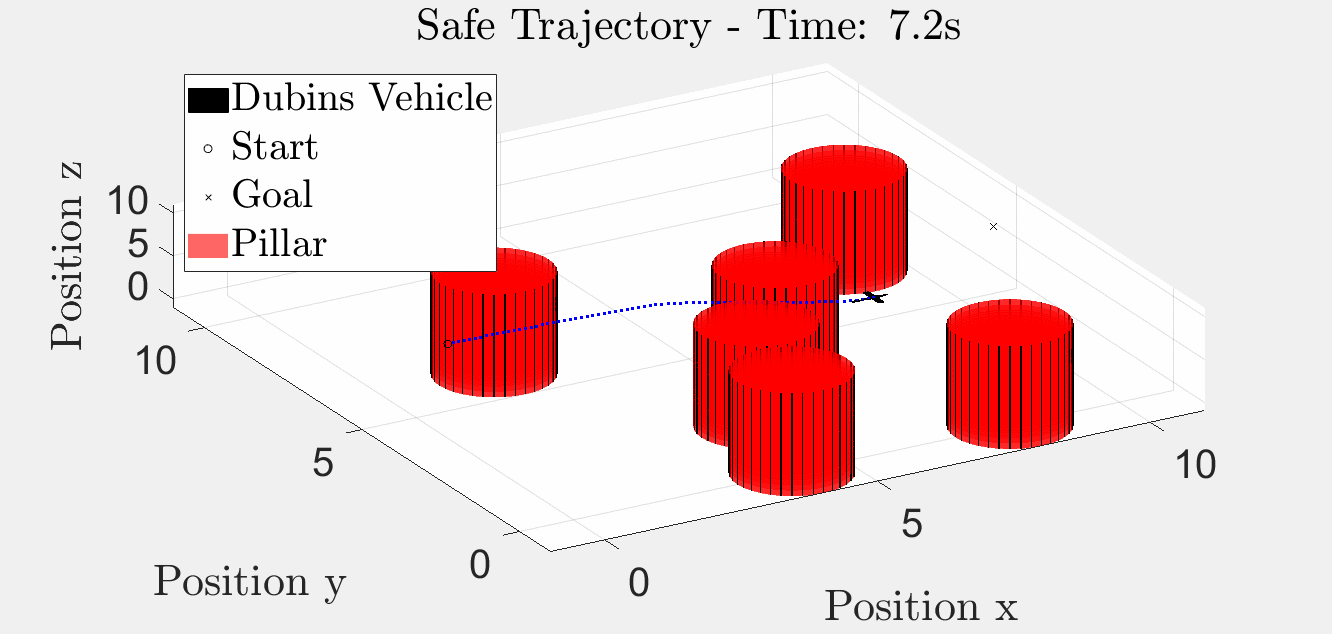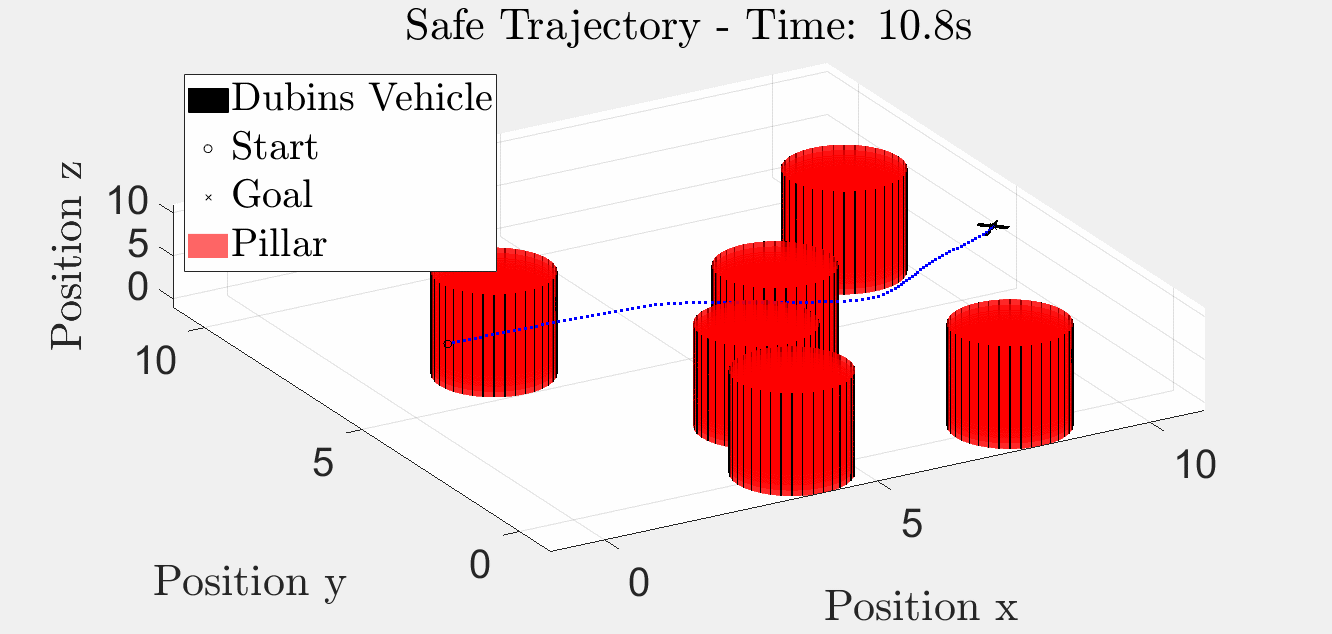
3-D animation